Data strucuture design & benchmark#
mmkv的数据结构都在/mmkv/algo中,主要包括:
ReservedArray
Slist
Blist
HashTable
HashSet(HashTable derived class)
Dictionary(HashTable wrapper)
AvlTree
TreeHashTable
AvlDictionary(TreeHashTable derived class)
这些数据结构均是STL-like风格,区别在于API命名风格不同。
ReservedArray#

ReservedArray是专门为HashTable准备的连续容器,不过相对std::vector,不支持append操作自动扩展,因为只有data和end两个指针维护一个内存区域。
除了这个区别,最大的区别就是ReservedArray支持reallocate,其默认采用的内存分配器是LibcAllocatorWithRealloc(与STL的默认分配器的区别在于::realloc())。具体来说,只有trivial类型和定义了静态数据成员static [constexpr] bool can_reallocate = true且默认构造函数不抛出异常的类才允许进行reallocate,其余的还是走老路子,即先分配新的内存区域再移动过去,释放原区域。
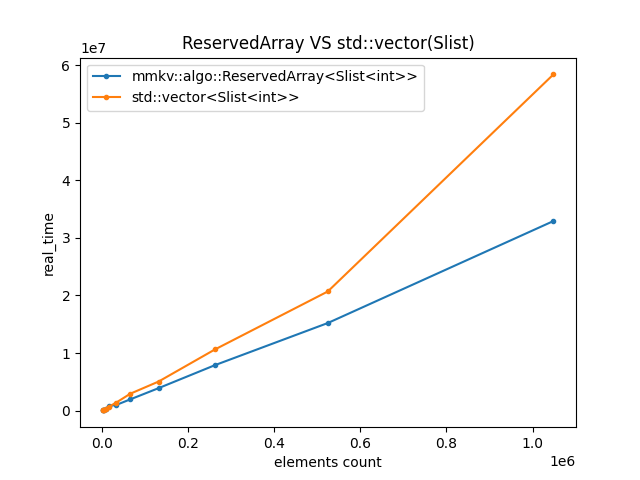
可见采用reallocate带来的性能提升是明显的
Slist#

Slist是与std::forward_list类似的单链表,区别在于Slist没有哨兵且没有成环(因为没有哨兵作为尾后迭代器),为了节省空间(哈希表分离列表法可能会有很多空槽占用哨兵)。
Blist#

Blist是类似std::list的双向链表,区别在于Blist没有哨兵且没有成环(同Slist的原因)。
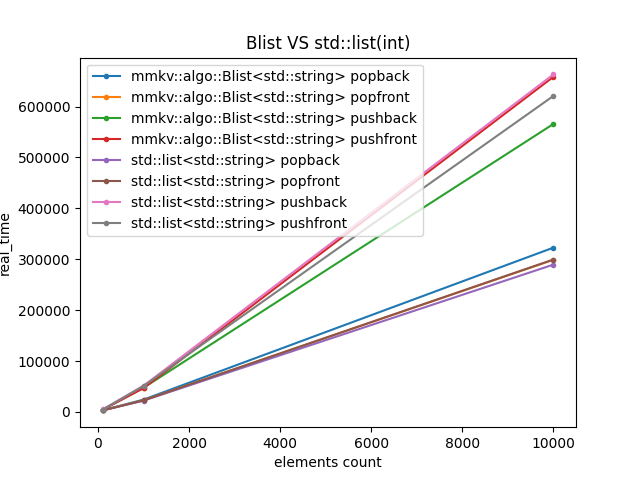
(注意,图中橙色与棕色几乎合并)
虽然Blist从操作优劣程度来看,是比std::list差的,但是差距不大,作为省空间的代价是可以接受的。
HashTable#
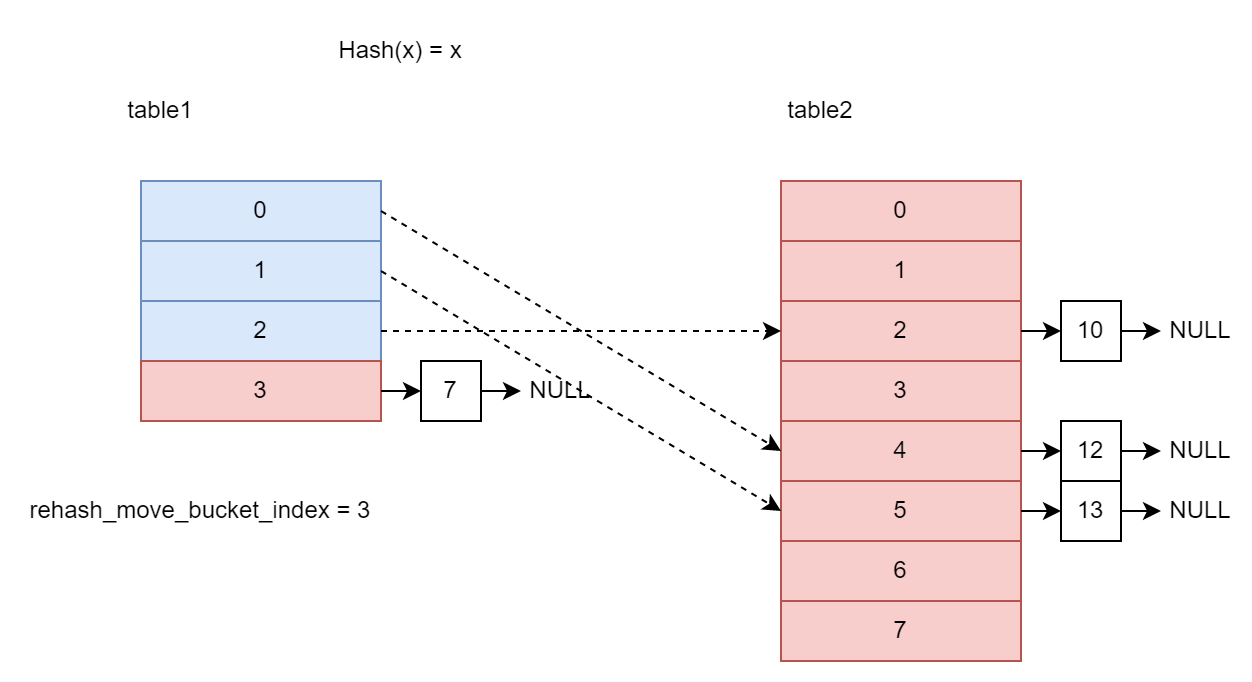
HashTable是基于Separate-list策略的哈希表,列表类型是Slist,但是rehash策略并不是一次移动所有桶子(bucket),而是每次读写操作移动一个桶子直到rehash完成,即所谓的递进式再散列(Incremental rehash)。除此之外,为了可以用
&代替%获得桶的索引,rehash呈两倍扩展,而不是选择最近的更大素数,尽管这会导致即使选用的哈希函数比较均一,在一定程度上会导致碰撞率上升而降低性能。这点可以通过更换列表类型缓解
不过该哈希表并没有针对迭代进行优化,因为一般这样做会降低点查询(point query)的性能,因此暂时不考虑这方面的优化。
HashSet#
HashSet是HashTable的子类,除了继承来的方法,还提供了三种方法支持对两个集合的交集,并集,差集的元素进行操作(传递回调)。
Dictionary#
Dictionary是HashTable的子类,差别不大,仅新增了更方便键值对的方法。
AvlTree#
mmkv的有序集合,我没有选择红黑树或跳表,首先,跳表的性能并没有平衡树好,其次,红黑树的高度并不是严格的O(lg(n))而是O(2lg(n+1))。因此对于读 > 写的mmkv而言高度更严格平衡的avl树更为适合。
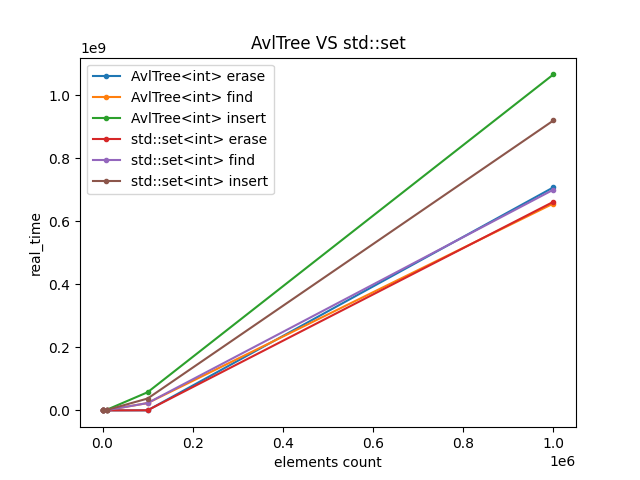
与红黑树相比,在插入和删除上更差,但是查询更好。符合预期结果。
TreeHashTable#
HashTable采用链表的弊端在HashTable中已经讲明。TreeHashTable选用的列表类型是平衡树(balanced-search-tree),可以使插入,删除,查询的算法复杂度维持在O(lgn),在一定程度上缓解了由于哈希函数和表大小带来的问题。
AvlDictionary#
AvlDictionary是AvlTreeMap(TreeHashTable的别名)的子类,列表类型是avl树。
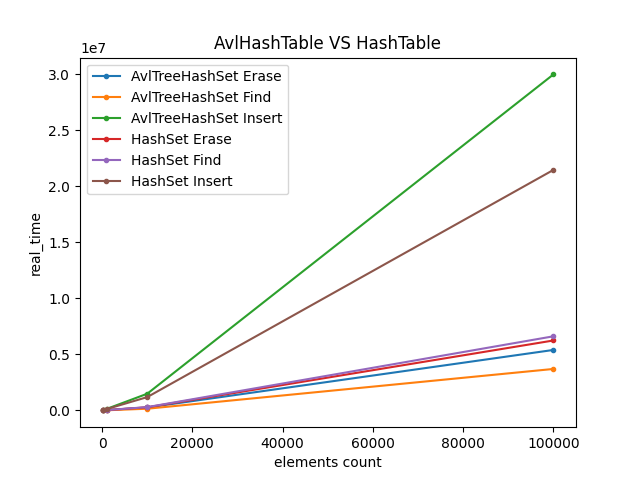
与基于链表的哈希表相比,使用avl树的哈希表在查询和删除上要更好,但是插入要差一些。