// include/forward_list/node_def.h /** * Throught BaseLinkedNode to split the detail of algorithm * from class template(ForwardList<>) * @note In C++, "typedef struct XXX { } XXX;" is not necessary in fact. * @see src/forward_list/algorithm.cc */ typedefstructBaseLinkedNode { structBaseLinkedNode* next = nullptr; } BaseLinkedNode;
/** * Represents the plain node * which has value(related template parameter) */ template<typename T> structLinkedNode : BaseLinkedNode { T val; };
/** * Represents the header sentinel. * Different from the plain node(LinkedNode<>), header doesn't maintains value domain, * it just maintains previous/next and count of elements. * @warning This is not STL-required, just useful for me. */ structHeader : BaseLinkedNode { BaseLinkedNode* prev = nullptr; size_t count = 0; };
/** * Because only the value of node is related with template parameter, * we can use @c BaseLinkedNode to split the detail of algorithm to avoid every class template * instantiation with implemetation itself. * * The push/insert_xxx() and extract_xxx() no need to consider the value of node */ voidpush_front(Header* header, BaseLinkedNode* new_node)noexcept; voidpush_back(Header* header, BaseLinkedNode* new_node)noexcept; voidinsert_after(Header* header, BaseLinkedNode* pos, BaseLinkedNode* new_node)noexcept;
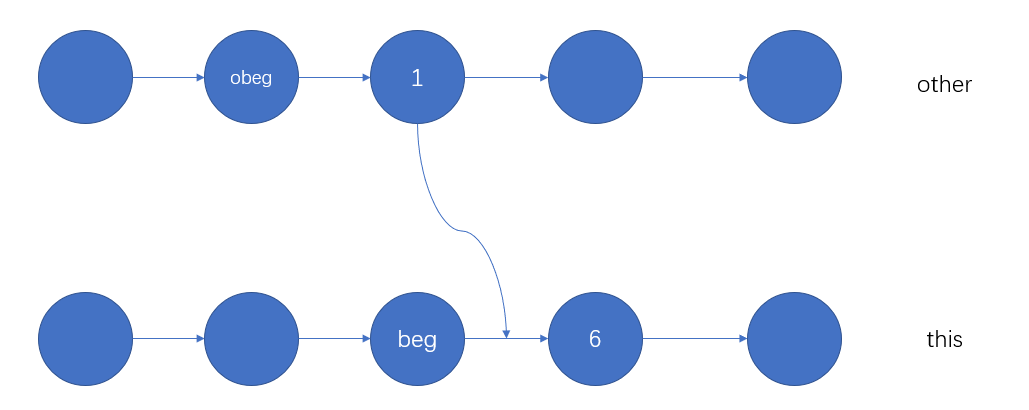
auto ret = header->next; header->next = header->next->next; if (FORWARD_LIST_EMPTY) { header->prev = header; } // Reset returned node, to avoid construct loop in some cases ret->next = nullptr;
BaseLinkedNode* extract_after(Header* header, BaseLinkedNode* pos)noexcept { ZASSERT(pos != nullptr, "The position argument must not be end()"); ZASSERT(!FORWARD_LIST_EMPTY, "ForwardList must be not empty"); ZASSERT(pos->next != nullptr, "The next node of the position argument mustn't be nullptr");
auto ret = pos->next;
// If pos->next is last element, update it if (ret == header->prev) { // FIXME Need to update head->prev = nullptr when pos == header header->prev = pos; }
BaseLinkedNode* extract_after(Header* header, BaseLinkedNode* first, BaseLinkedNode* last)noexcept { // The length of the range must be 1 at least if (first->next != last) { BaseLinkedNode* old_next;
// If last is the end iterator, indicates the header_->prev need to update if (last == nullptr) { header->prev = first; }
auto first_next = first->next; first->next = last;
template<typename Alloc> using HeaderAllocator = typename Alloc::template rebind<Header>::other;
template<typename T, typename Alloc> using NodeAllocator = typename Alloc::template rebind<LinkedNode<T>>::other;
/** * EBCO * Need two allocator: header and node * This class also manage the header allocate and deallocate * but don't construct and destroy it, it just a POD object. */ template<typename T, typename Alloc=std::allocator<T>> class ForwardListBase : protected HeaderAllocator<Alloc>, protected NodeAllocator<T, Alloc> { protected: using AllocTraits = std::allocator_traits<HeaderAllocator<Alloc>>;
template<typename T, typename Alloc=std::allocator<T>> class ForwardList : protected forward_list_detail::ForwardListBase<T, Alloc> { public: //... private: // Expose the header_ in Base class. // This is necessary for base class template. using Base::header_; };
// Insert after header template<typename ...Args> voidemplace_front(Args&&... args){ push_front(create_node(STD_FORWARD(Args, args)...)); } // It is may be better for builtin type that use value-passed parameter. // But we can not suppose the move operation for ValueType is cheap // Thus, I still write const&/&& or better. voidpush_front(ValueType const& val){ push_front(create_node(val)); } voidpush_front(ValueType&& val){ push_front(create_node(std::move(val))); }
// Insert before header // Not standard required template<typename ...Args> voidemplace_back(Args&&... args){ push_back(create_node(STD_FORWARD(Args, args)...)); } voidpush_back(ValueType const& val){ push_back(create_node(val)); } voidpush_back(ValueType&& val){ push_back(create_node(std::move(val))); }
// Based on Node, thus we can reuse extracted node(throught call extract_xxx()) // Maybe this is the implementation function of std::forward_list<> // But I expose these. // Not standard required inlinevoidpush_front(Node* new_node)noexcept; inlinevoidpush_back(Node* new_node)noexcept; inlinevoidinsert_after(ConstIterator pos, Node* new_node);
// The implematation detial of pop_front() and erase_after() // But these don't free the node in fact, just remove it from list // The user can reuse the returnd node // Not standard required inline Node* extract_front()noexcept; inline Node* extract_after(ConstIterator pos)noexcept;
基本都是wrapper,除了clear():
1 2 3 4 5 6 7 8 9 10 11
template<typename T, typename A> voidFORWARD_LIST_TEMPLATE::clear() { while (header_->next) { auto node = header_->next; header_->next = node->next; drop_node(node); }
Base::reset(); }
基本上没什么好讲的
search API
1 2 3 4 5 6 7 8 9
// Search the before iterator of the given value. // It's useful for calling erase_after() and insert_after(). // Not standard required Iterator search_before(ValueType const& val, ConstIterator pos); template<typename UnaryPred> Iterator search_before_if(UnaryPred pred, ConstIterator pos); Iterator search_before(ValueType const& val){ returnsearch_before(val, cbefore_begin()); } template<typename UnaryPred> Iterator search_before(UnaryPred pred){ returnsearch_before(pred, cbefore_begin()); }
template<typename T, typename A> voidFORWARD_LIST_TEMPLATE::splice_after(ConstIterator pos, Self& list) { // If list is empty, // it is wrong to update prev. if (list.empty()) return ;
auto pos_node = pos.to_iterator().extract(); auto old_next = pos_node->next;
if (pos == before_end()) { header_->prev = list.before_end().extract(); }
pos_node->next = list.begin().extract(); list.before_end().extract()->next = old_next; header_->count += list.size(); list.reset(); ZASSERT(list.empty(), "The list must be empty"); }
// In C++20, the return type is modified to size_type(i.e. SizeType here). // It indicates the number of removed elements SizeType remove(ValueType const& val); template<typename UnaryPred> SizeType remove_if(UnaryPred pred);
voidreverse(Header* header)noexcept { // Or use recurrsion to implemetation std::vector<BaseLinkedNode*> nodes; nodes.reserve(header->count);
while (!FORWARD_LIST_EMPTY) { nodes.push_back(extract_front(header)); } assert(FORWARD_LIST_EMPTY); assert(nodes.size() == nodes.capacity());
using SizeType = decltype(header->count); for (SizeType i = 0; i < nodes.size(); ++i) { push_front(header, nodes[i]); } }
unique
1 2 3 4 5
// In C++20, the return type is modified to size_type(i.e. SizeType here). // It indicates the number of removed elements SizeType unique(); template<typename BinaryPred> SizeType unique(BinaryPred pred);
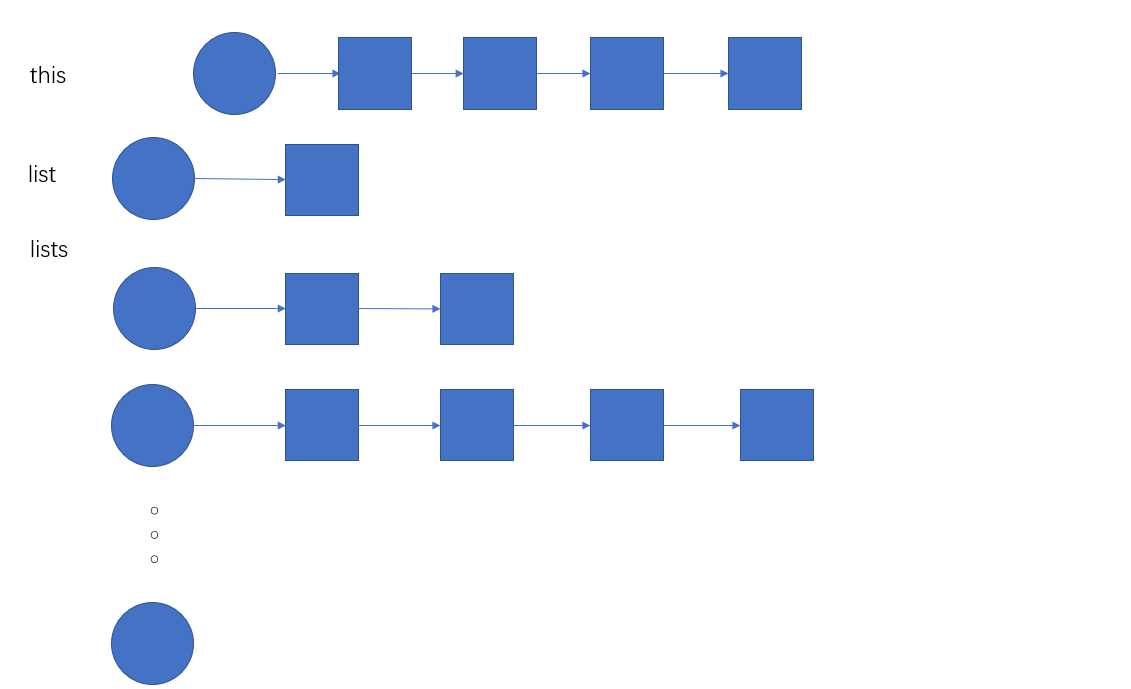
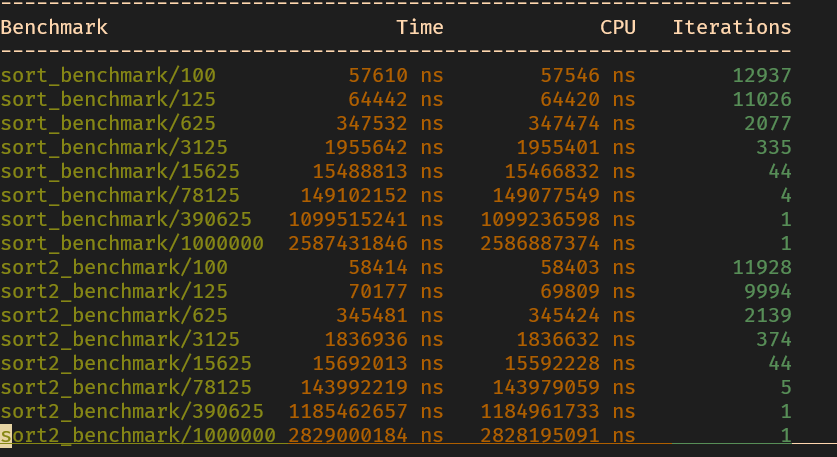
template<typename T, typename A> voidFORWARD_LIST_TEMPLATE::sort() { // TODO Optimization // lists store non-header list // To small list, maybe better a little. // It is not significant for large list. Self lists[64]; Self list; int8_t end_of_lists = 0;
while (!empty()) { list.push_front(extract_front()); for (int8_t i = 0; ; ++i) { if (lists[i].empty()) { list.swap(lists[i]); if (i == end_of_lists) end_of_lists++; break; } else { // Merge non-empty list // larger list merge shorter list if (lists[i].size() > list.size()) { lists[i].merge(list); list.swap(lists[i]); } else list.merge(lists[i]); } } } assert(list.empty());
for (int i = end_of_lists - 1; i >= 0; --i) { list.merge(lists[i]); }
*this = std::move(list); }
template<typename T, typename A> voidFORWARD_LIST_TEMPLATE::sort2() { ForwardList less; ForwardList equal; ForwardList larger; if (size() < 2) { return ; }