
最短路径——Dijkstra
Dijkstra
Dijkstra是一种求得从一个顶点出发到达终点最短路径的算法。
Dijkstra本质就是贪心算法,它不是一次求得从起点到终点的最短路径,而是一步步求得它们之间顶点的最短路径,基于已经求出的最短路径的基础上,求得更远顶点的最短路径,最终得到你要的结果。
引入概念
点权:
点权值就是源点到该顶点的最短路径(贪心算法必然的结果),下面的D和dist都是存储点权值的vector,将它们输出可以得到源点到各顶点的最短路径。
Dijkstra实现关键——松弛操作
松弛操作是Dijkstra算法的基础操作:如果存在一条从u到v的边,那么从s到v的一条新路径是将边 w(u,v)添加到从s到u的路径尾部来拓展一条从s到v的路径。这条路径的长度是d[u]+w(u,v)。如果这个值比目前已知的d[v]的值要小,那么可以用这个值来替代当前d[v]中的值。松弛边的操作一直运行到所有的d[v]都代表从s到v的最短路径的长度值。松弛操作正是贪心算法的体现。
PS:d[x]表示的是源点到x的最短路径。
基本思想
- 将起点权值置为0,其他顶点置为无穷大
- 集合A装所有顶点
- while A不为空时
pop出A中最小权值的顶点a
对a指向的每个顶点x,x的权值设为min(a+arc(a,x),x)
动态演示
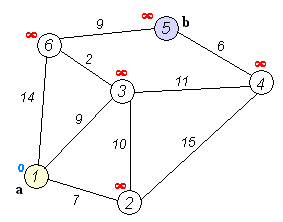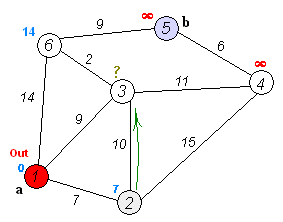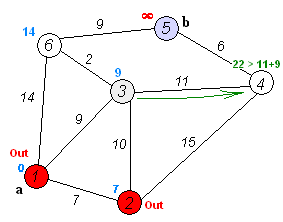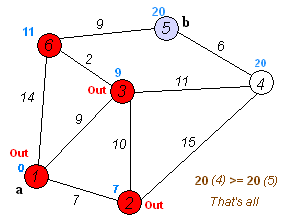
(尽管图上没有显示4和5out,但实际上是要pop的,而且4还要去访问下5,而5的邻接边的顶点都已经访问过了,比较是必然失败的,可设置bool数组记录访问过的顶点来避免重复的比较)
实现代码
1 | //direct是有向依据,numv是顶点个数,nume是边数 |
测试代码
1 | int main () |
堆优化
运用STL中优先队列的性质可以构造小顶堆(或大顶堆),
实现代码
1 | typedef pair<int,int> ipair; |
测试代码
1 | int main () |
代码部分说明:
!final[u]
我们在取出最小权值点其实要对该点进行判定,因为可能是访问过的顶点,堆中存在两个相同顶点的pair,一个是松弛过的,一个是之前的,当然松弛过的肯定会优先弹出来,这样之前的再弹出来也就没意义了,因此要进行一次判定。
!final[s]
同时,在对最小权值点邻接边进行遍历时,也需要判定是否访问过,因为反向吃回头草必然不能松弛。
实例讲解
无向图没啥好讲的,讲下有向图(无权)吧:
(如果是1开始的,可以在调用函数时令其减一,所以下面都会比图上数字少1)
源点设为1,无权设边权都为1,即边数,dist[0]=0,
1)看1的邻接边只有5,5的点权为∞,因此dist[4]=1,即1到5的最短路径为1;
2)接下来看5的邻接边有6和2,根据一开始压入的顺序决定谁先开始,但是不管谁先都一样,因为小顶堆的性质决定了谁先pop,现在6的点权是∞,所以dist[5]=2;
3)接下来看5的邻接边2,2的点权为∞,所以dist[1]=2;
4)现在pop顶点2,2的邻接边有4,1,但是1不予考虑,俗话说的好:好牛不吃回头草,因为对于访问过的结点,dist[u]+weight
7)pop顶点4,4的邻接边有1,3,但是都是已经访问过的,比较肯定失败;
8)现在优先队列已空,结束while循环,输出源点到各顶点的最小路径后结束函数。
时间复杂度分析
伪代码:1
2
3
4
5
6
7
81 INITIALIZE-SINGLE-SOURCE(G, s)
2 S ← Ø //S存储已访问顶点
3 Q ← V[G] //Q存储所有顶点
4 while Q ≠ Ø
5 do u ← EXTRACT-MIN(Q) //exact_min
6 S ← S ∪{u}
7 for each vertex v ∈ Adj[u]
8 do RELAX(u, v, w) //decrease_key
Tn=O(e·Tdk+v·Tem),Tdk表示decrease_key的时间复杂度,Tem表示exact_min的时间复杂度,这是因为decrease_key体现在松弛操作,松弛操作需要遍历最小权值点的邻接边,最多遍历所有边,以最多遍历的那次代表其他顶点的松弛,所以是e(Big O),而exact_min与顶点数有关,最坏需要遍历所有顶点(一般版本就是要遍历所有顶点),所以是v。
一般版本的exact_min是通过for循环,最坏遍历所有顶点,所以是O(v),decrease_key很简单,不需要调整最小路径数组,为O(1),那么时间复杂度为O(e+v^2)=O(v^2),但我们可以通过优先队列来优化,优先队列可以自动进行堆排序,这个维护堆的过程时间复杂度最坏为O(logv),而exact_min的过程堆排序进行为O(logv),decrease_key的过程需要维护堆也是O(logv)所以堆优化的Dijkstra的时间复杂度为O((e+v)logv),取同阶时间复杂度为O(nlogn)>O(n^2)。





